基于MySQL的存储引擎与日志说明(全面讲解)
1.1 存储引擎的介绍
1.1.1 文件系统存储
文件系统:操作系统组织和存取数据的一种机制。文件系统是一种软件。
类型:ext2 3 4 ,xfs 数据。 不管使用什么文件系统,数据内容不会变化,不同的是,存储空间、大小、速度。
1.1.2 mysql数据库存储
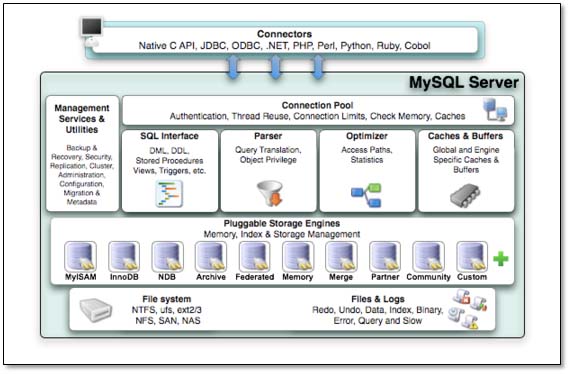
MySQL引擎: 可以理解为,MySQL的“文件系统”,只不过功能更加强大。
MySQL引擎功能: 除了可以提供基本的存取功能,还有更多功能事务功能、锁定、备份和恢复、优化以及特殊功能。
1.1.3 MySQL存储引擎种类
MySQL 提供以下存储引擎:
InnoDB、MyISAM (最常用的两种)MEMORY、ARCHIVE、FEDERATED、EXAMPLEBLACKHOLE、MERGE、NDBCLUSTER、CSV
1.1.4 innodb与myisam对比
InnoDb引擎
支持ACID的事务,支持事务的四种隔离级别;
支持行级锁及外键约束:因此可以支持写并发;
不存储总行数;
一个InnoDb引擎存储在一个文件空间(共享表空间,表大小不受操作系统控制,一个表可能分布在多个文件里),也有可能为多个(设置为独立表空,表大小受操作系统文件大小限制,一般为2G),受操作系统文件大小的限制;
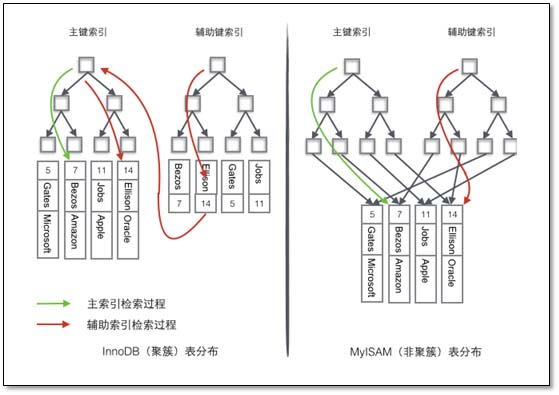
主键索引采用聚集索引(索引的数据域存储数据文件本身),辅索引的数据域存储主键的值;因此从辅索引查找数据,需要先通过辅索引找到主键值,再访问辅索引;最好使用自增主键,防止插入数据时,为维持B+树结构,文件的大调整。
Innodb的主索引结构如下:

MyISAM引擎
不支持事务,但是每次查询都是原子的;
支持表级锁,即每次操作是对整个表加锁;
存储表的总行数;
一个MYISAM表有三个文件:索引文件、表结构文件、数据文件;
采用菲聚集索引,索引文件的数据域存储指向数据文件的指针。辅索引与主索引基本一致,但是辅索引不用保证唯一性。
MYISAM的主索引结构如下:
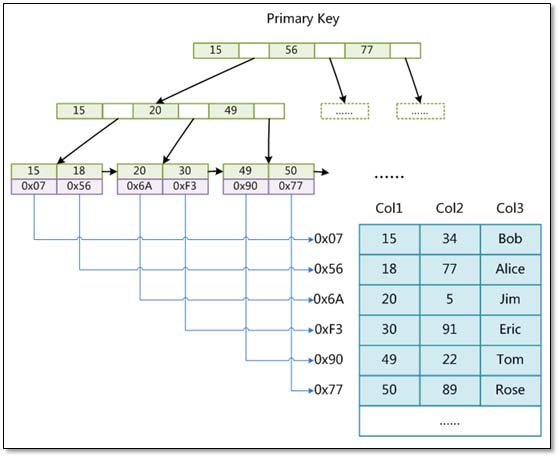
两种索引数据查找过程如下:
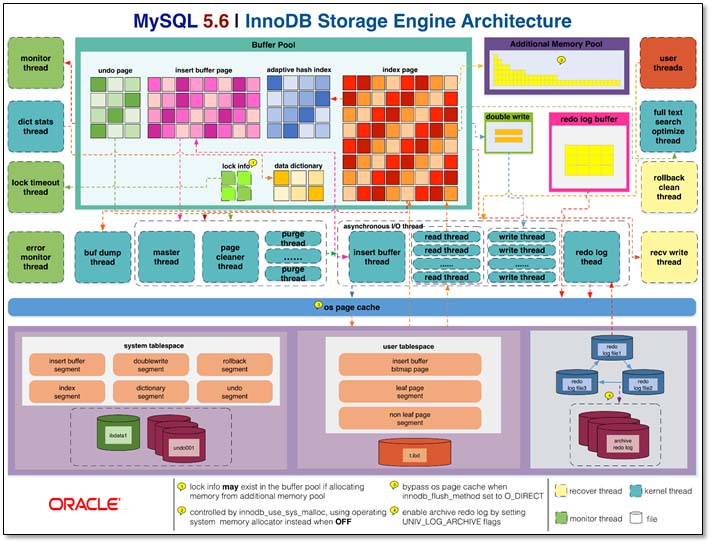
1.2 innodb存储引擎
在MySQL5.5版本之后,默认的存储引擎,提供高可靠性和高性能。
1.2.1 Innodb引擎的优点
a) 事务安全(遵从ACID)b) MVCC(Multi-Versioning Concurrency Control,多版本并发控制)c) InnoDB行级锁d) 支持外键引用完整性约束e) 出现故障后快速自动恢复(crash safe recovery)f) 用于在内存中缓存数据和索引的缓冲区池(buffer pool(data buffer page log buffer page) 、undo buffer page)g) 大型数据卷上的最大性能h) 将对表的查询与不同存储引擎混合i) Oracle样式一致非锁定读取(共享锁)j) 表数据进行整理来优化基于主键的查询(聚集索引)
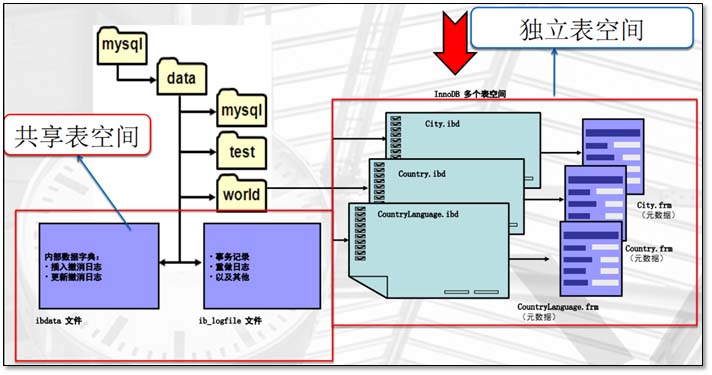
功能1、使用 SELECT 确认会话存储引擎:SHOW CREATE TABLE City\GSHOW TABLE STATUS LIKE 'CountryLanguage'\G SELECT TABLE_NAME, ENGINE FROM INFORMATION_SCHEMA.TABLESWHERE TABLE_NAME = 'City'AND TABLE_SCHEMA = 'world_innodb'\G 假如5.1版本数据库所有生产表都是myisam的。 使用mysqldump备份后,一点要替换备份的文件中的engine(引擎)字段,从myisam替换为innodb(可以使用sed命令),否则迁移无任何意义。 数据库升级时,要注意其他配套设施的兼容性,注意代码能否兼容新特性。 1.2.4 设置存储引擎 1、在启动配置文件中设置服务器存储引擎: [mysqld]default-storage-engine=<Storage Engine> SET @@storage_engine=<Storage Engine>; CREATE TABLE t (i INT) ENGINE = <Storage Engine>; 1.3.1 InnoDB 系统表空间特性 默认情况下,InnoDB 元数据、撤消日志和缓冲区存储在系统“表空间”中。 这是单个逻辑存储区域,可以包含一个或多个文件。 每个文件可以是常规文件或原始分区。 最后的文件可以自动扩展。 1.3.2 表空间的定义 表空间:MySQL数据库存储的方式 表空间中包含数据文件 MySQl表空间和数据文件是1:1的关系 共享表空间除外,是可以1:N关系
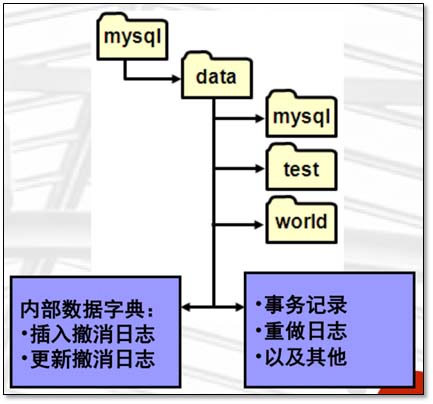
1.3.3 表空间类型 1、共享表空间:ibdata1~ibdataN,一般是2-3个 2、独立表空间:存放在指定库目录下,例如data/world/目录下的city.ibd 表空间位置(datadir): data/目录下 1.3.4 系统表空间的存储内容 共享表空间(物理存储结构) ibdata1~N 通常被叫做系统表空间,是数据初始化生成的 系统元数据,基表数据,除了表内容数据之外的数据。 tmp 表空间(一般很少关注) undo日志 :数据--回滚数据(回滚日志使用) redo日志 :ib_logfile0~N 存放系统的innodb表的一些重做日志。 说明:undo日志默认实在ibdata中的,在5.6以后是可以单独定义的。 tmp 表空间在5.7版本之后被移出了ibdata1,变为ibtmp1 在5.5版本之前,所有的应用数据也都默认存放到了ibdata中。 独立表空间(一个存储引擎的功能) 在5.6之后,默认的情况下会单表单独存储到独立表空间文件 除了系统表空间之外,InnoDB 还在数据库目录中创建另外的表空间,用于每个 InnoDB 表的 .ibd 文件。 InnoDB 创建的每个新表在数据库目录中设置一个 .ibd 文件来搭配表的.frm 文件。 可以使用 innodb_file_per_table 选项控制此设置,更改该设置仅会更改已创建的新表的默认值。。
1.3.5 设置共享表空间 查看当前的共享表空间设置 mysql> show variables like 'innodb_data_file_path';+-----------------------+------------------------+| Variable_name | Value |+-----------------------+------------------------+| innodb_data_file_path | ibdata1:12M:autoextend |+-----------------------+------------------------+row in set (0.00 sec) 一般是在初始搭建环境的时候就配置号,预设值一般为1G;且最后一个为自动扩展。 [root@db02 world]# vim /etc/my.cnf[mysqld]innodb_data_file_path=ibdata1:76M;ibdata2:100M:autoextend mysql> show variables like 'innodb_data_file_path';+-----------------------+-------------------------------------+| Variable_name | Value |+-----------------------+-------------------------------------+| innodb_data_file_path | ibdata1:76M;ibdata2:100M:autoextend |+-----------------------+-------------------------------------+row in set (0.00 sec) 独立表空间在5.6版本是默认开启的。 独立表空间注意事项:不开起独立表空间,共享表空间会占用很大 mysql> show variables like '%per_table%';+-----------------------+-------+| Variable_name | Value |+-----------------------+-------+| innodb_file_per_table | ON |+-----------------------+-------+row in set (0.00 sec) 关闭独立表空间 (0是关闭,1是开启) [root@db02 clsn]# vim /etc/my.cnf[mysqld]innodb_file_per_table=0 mysql> show variables like '%per_table%' ;+-----------------------+-------+| Variable_name | Value |+-----------------------+-------+| innodb_file_per_table | OFF |+-----------------------+-------+row in set (0.00 sec) innodb_file_per_table=0 关闭独立表空间innodb_file_per_table=1 开启独立表空间,单表单存储 一组数据操作执行步骤,这些步骤被视为一个工作单元 用于对多个语句进行分组,可以在多个客户机并发访问同一个表中的数据时使用。 所有步骤都成功或都失败 如果所有步骤正常,则执行,如果步骤出现错误或不完整,则取消。 简单来说事务就是:保证工作单元中的语句同时成功或同时失败。
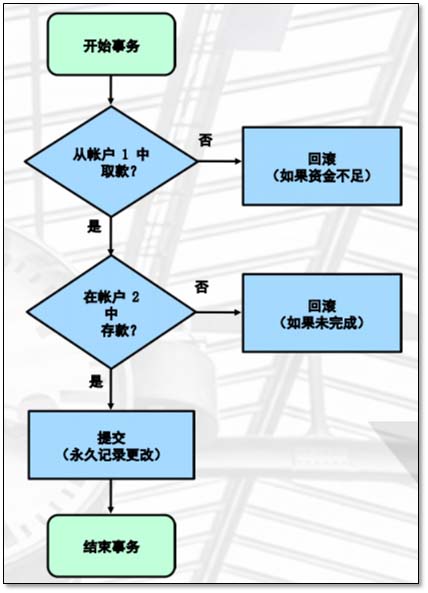
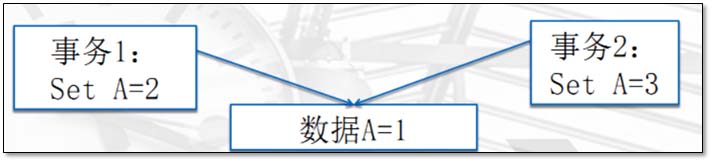
事务处理流程示意图 1.4.1 事务是什么 与其给事务定义,不如说一说事务的特性。众所周知,事务需要满足ACID四个特性。 A(atomicity) 原子性。 一个事务的执行被视为一个不可分割的最小单元。事务里面的操作,要么全部成功执行,要么全部失败回滚,不可以只执行其中的一部分。 所有语句作为一个单元全部成功执行或全部取消。updata t1 set money=10000-17 where id=wxid1updata t1 set money=10000+17 where id=wxid2 一个事务的执行不应该破坏数据库的完整性约束。如果上述例子中第2个操作执行后系统崩溃,保证A和B的金钱总计是不会变的。 如果数据库在事务开始时处于一致状态,则在执行该事务期间将保留一致状态。 updata t1 set money=10000-17 where id=wxid1 updata t1 set money=10000+17 where id=wxid2 在以上操作过程中,去查自己账户还是10000 通常来说,事务之间的行为不应该互相影响。然而实际情况中,事务相互影响的程度受到隔离级别的影响。文章后面会详述。 事务之间不相互影响。在做操作的时候,其他人对这两个账户做任何操作,在不同的隔离条件下,可能一致性保证又不一样 隔离级别 隔离级别会影响到一致性。 read-uncommit X read-commit 可能会用的一种级别 repeatable-read 默认的级别,和oracle一样的 SERIALIZABLE 严格的默认,一般不会用 D(durability) 持久性。 事务提交之后,需要将提交的事务持久化到磁盘。即使系统崩溃,提交的数据也不应该丢失。 保证数据落地,才算事务真正安全 常用的事务控制语句: START TRANSACTION(或 BEGIN):显式开始一个新事务 COMMIT:永久记录当前事务所做的更改(事务成功结束) ROLLBACK:取消当前事务所做的更改(事务失败结束) SAVEPOINT:分配事务过程中的一个位置,以供将来引用 ROLLBACK TO SAVEPOINT:取消在 savepoint 之后执行的更改 RELEASE SAVEPOINT:删除 savepoint 标识符 SET AUTOCOMMIT:为当前连接禁用或启用默认 autocommit模式 在MySQL5.5开始,开启事务时不再需要begin或者start transaction语句。并且,默认是开启了Autocommit模式,作为一个事务隐式提交每个语句。 在有些业务繁忙企业场景下,这种配置可能会对性能产生很大影响,但对于安全性上有很大提高。将来,我们需要去权衡我们的业务需求去调整是否自动提交。 注意:在生产中,根据实际需求选择是否可开启,一般银行类业务会选择关闭。 查看当前autocommit状态: mysql> show variables like '%autoc%';+---------------+-------+| Variable_name | Value |+---------------+-------+| autocommit | ON |+---------------+-------+row in set (0.00 sec) [root@db02 world]# vim /etc/my.cnf[mysqld]autocommit=0 mysql> show variables like '%autoc%';+---------------+-------+| Variable_name | Value |+---------------+-------+| autocommit | OFF |+---------------+-------+row in set (0.00 sec)mysql> select @@autocommit;+--------------+| @@autocommit |+--------------+| 0 |+--------------+row in set (0.00 sec) 优点:数据安全性好,每次修改都会落地 缺点:不能进行银行类的交易事务、产生大量小的IO 1.4.4 导致提交的非事务语句: DDL语句: (ALTER、CREATE 和 DROP)DCL语句: (GRANT、REVOKE 和 SET PASSWORD)锁定语句:(LOCK TABLES 和 UNLOCK TABLES) TRUNCATE TABLELOAD DATA INFILESELECT FOR UPDATE START TRANSACTIONSET AUTOCOMMIT = 1
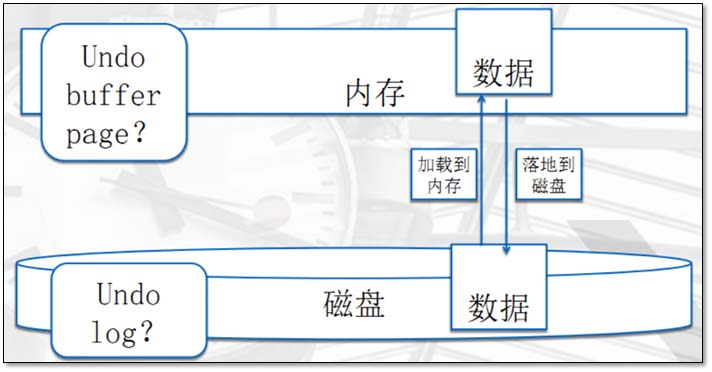
1.5.1 事务日志undo undo原理: Undo Log的原理很简单,为了满足事务的原子性,在操作任何数据之前,首先将数据备份到一个地方(这个存储数据备份的地方称为Undo Log)。然后进行数据的修改。 如果出现了错误或者用户执行了ROLLBACK语句,系统可以利用Undo Log中的备份将数据恢复到事务开始之前的状态。 除了可以保证事务的原子性,Undo Log也可以用来辅助完成事务的持久化。
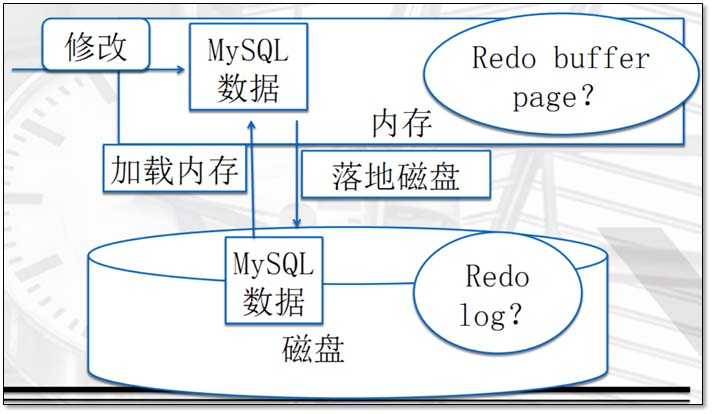
undo是什么? undo,顾名思义“回滚日志”,是事务日志的一种。 作用是什么? 在事务ACID过程中,实现的是“A“原子性的作用。 用Undo Log实现原子性和持久化的事务的简化过程 假设有A、B两个数据,值分别为1,2。 A.事务开始. B.记录A=1到undo log. C.修改A=3. D.记录B=2到undo log. E.修改B=4. F.将undo log写到磁盘。 G.将数据写到磁盘。 H.事务提交 A. 更新数据前记录Undo log。B. 为了保证持久性,必须将数据在事务提交前写到磁盘。只要事务成功提交,数据必然已经持久化。C. Undo log必须先于数据持久化到磁盘。如果在G,H之间系统崩溃,undo log是完整的,可以用来回滚事务。D. 如果在A-F之间系统崩溃,因为数据没有持久化到磁盘。所以磁盘上的数据还是保持在事务开始前的状态。 每个事务提交前将数据和Undo Log写入磁盘,这样会导致大量的磁盘IO,因此性能很低。如果能够将数据缓存一段时间,就能减少IO提高性能。但是这样就会丧失事务的持久性。 因此引入了另外一种机制来实现持久化,即Redo Log. 1.5.2 事务日志redo redo原理: 和Undo Log相反,Redo Log记录的是新数据的备份。在事务提交前,只要将Redo Log持久化即可,不需要将数据持久化。当系统崩溃时,虽然数据没有持久化,但是Redo Log已经持久化。 系统可以根据Redo Log的内容,将所有数据恢复到最新的状态。
Redo是什么? redo,顾名思义“重做日志”,是事务日志的一种。 作用是什么? 在事务ACID过程中,实现的是“D”持久化的作用。 Undo + Redo事务的简化过程 假设有A、B两个数据,值分别为1,2. A.事务开始. B.记录A=1到undo log. C.修改A=3. D.记录A=3到redo log. E.记录B=2到undo log. F.修改B=4. G.记录B=4到redo log. H.将redo log写入磁盘。 I.事务提交 A. 为了保证持久性,必须在事务提交前将Redo Log持久化。 B. 数据不需要在事务提交前写入磁盘,而是缓存在内存中。 C. Redo Log 保证事务的持久性。 D. Undo Log 保证事务的原子性。 E. 有一个隐含的特点,数据必须要晚于redo log写入持久存储。 innodb_flush_log_at_trx_commit=1/0/2 什么是“锁”? “锁”顾名思义就是锁定的意思。 “锁”的作用是什么? 在事务ACID过程中,“锁”和“隔离级别”一起来实现“I”隔离性的作用。
锁的粒度: 1、MyIasm:低并发锁——表级锁 2、Innodb:高并发锁——行级锁 四种隔离级别: READ UNCOMMITTED 许事务查看其他事务所进行的未提交更改READ COMMITTED 允许事务查看其他事务所进行的已提交更改REPEATABLE READ****** 确保每个事务的 SELECT 输出一致; InnoDB 的默认级别SERIALIZABLE 将一个事务的结果与其他事务完全隔离 表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。 仅从锁的角度来说:表级锁更适合于以查询为主,只有少量按索引条件更新数据的应用,如Web应用;而行级锁则更适合于有大量按索引条件并发更新少量不同数据,同时又有并发查询的应用,如一些在线事务处理(OLTP)系统。 1.6 MySQL 日志管理 1.6.1 MySQL日志类型简介 日志的类型的说明:
|